今天下載Llama3.1語言模型,並且會實際問問題。
Llama3模型是Meta發布的開源大型語言模型,與Llama2相比,Llama3使用了15兆個Token的資料來進行預訓練,是Llama2使用資料量的7倍大。
Llama3的特色可以總結成以下三點:
1. 增強多語言和程式能力: 它使用了超過 15 兆個訓練數據,並涵蓋 30 種語言,提升了多語言處理和程式碼相關任務的表現。
2. 更有效的文本編碼: 擴展詞彙量和 Grouped-Query Attention 技術,使模型在處理長文本時更加高效。
3. 先進的微調技術: 使用強化學習和指令微調,顯著提升在推理和程式任務中的表現。
步驟會從昨天Open WebUI介面開始接續。
步驟一: 將軟體設定語言改成【繁體中文】
按個人帳號頭貼進入【設定】,再點選【語言】,接者改成繁體中文。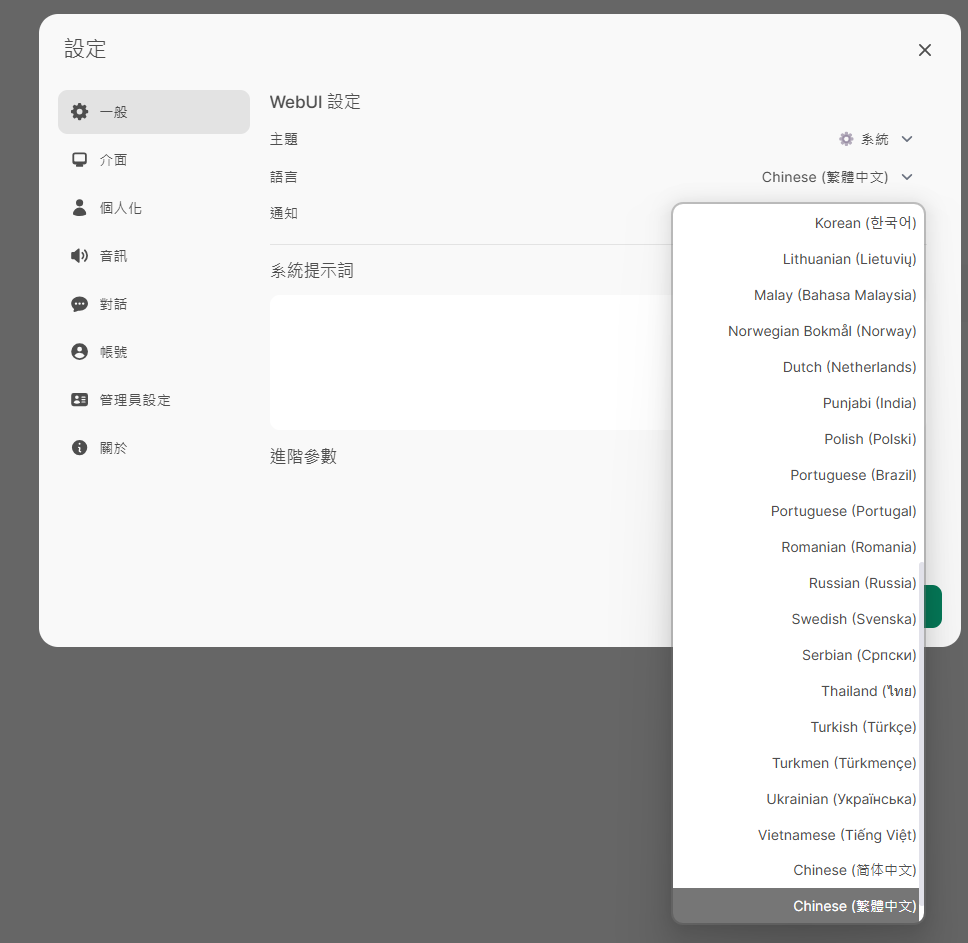
步驟二: 從下載Llama3.1模型
一樣從個人帳號頭貼進入,點選【管理員控制台】設定的【模型】,進入下方圖示裡的連結。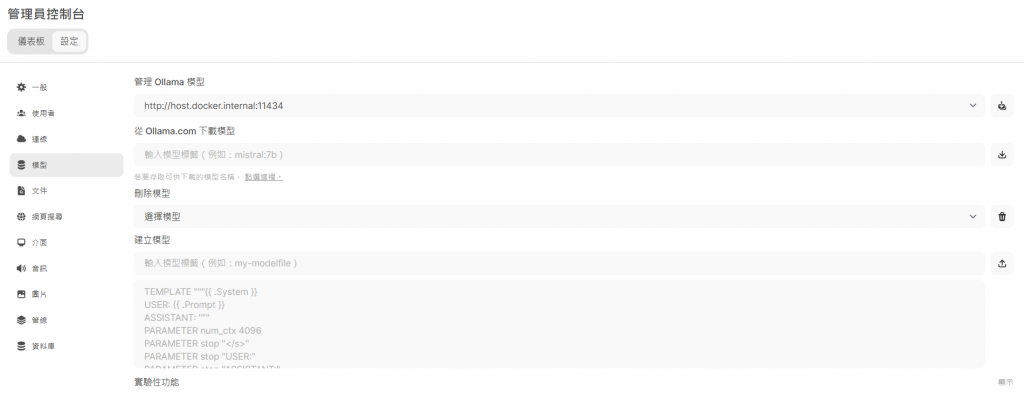
進入Ollama官網後找llama3.1模型。
Ollama幫大家整理目前最受歡迎的語言模型,若希望下載其他模型也可以直接複製模型名稱。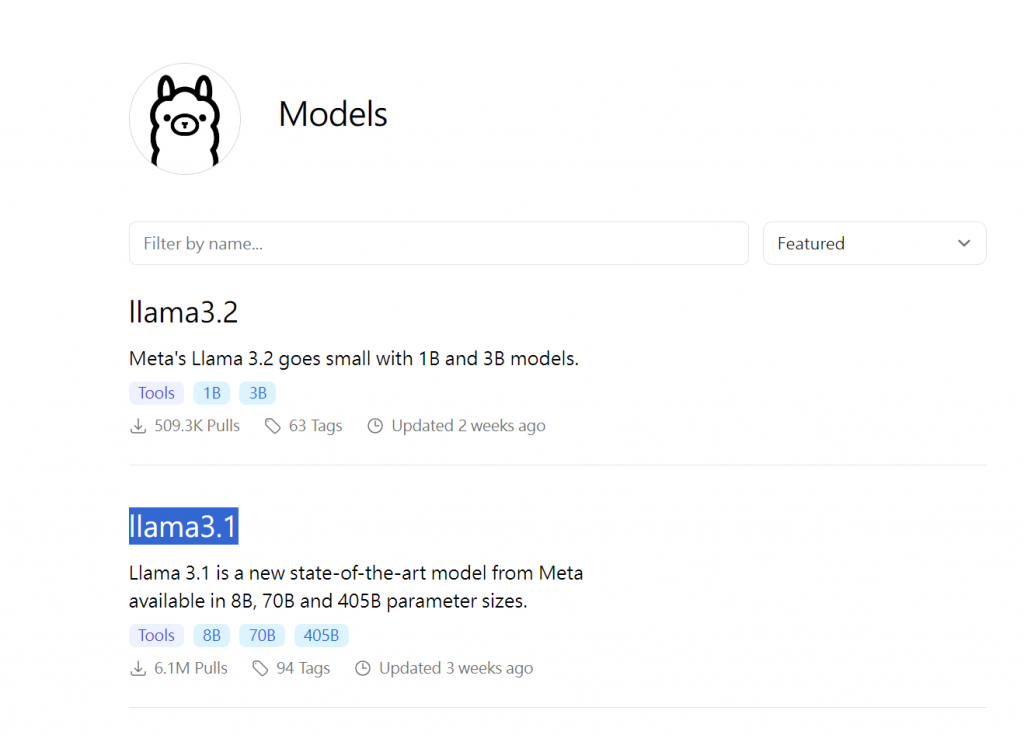
將名稱複製到剛剛輸入模型標籤的地方,並點選下載圖示,即可開始下載。
步驟三: 使用llama3.1對話
下載完成後,回到工具列的【新增對話】,從左上角【選擇模型】中選擇llama3.1模型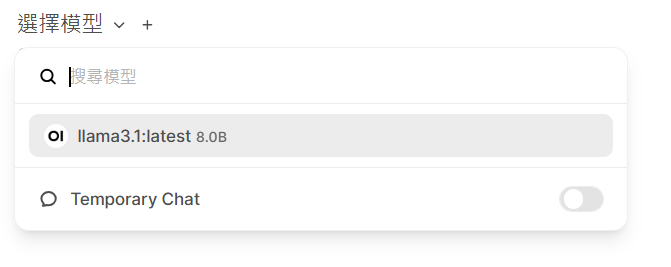
輸入指令,即可開始對話,成功~


 iThome鐵人賽
iThome鐵人賽